
我们在编写程序中免不了要涉及到通过正则表达式找到该字符串中有用的一部分。
那么既然可以通过正则表达式找到这一段字符串,可不可以再将这一段字符串给提取出来呢?答案是可以的。
我们需要怎么去提取所匹配当前正则表达式的字符串呢?
我们可以去使用jdk自带的工具类完成此操作,当然我们得模拟一个使用的场景来完成此次测试。
- 使用场景:使用阿里云的oss将图片上传之后,我们需要从oss中删除该图片,就必须得用到图片名称,因此需要将图片名称提取出来。
- 这里我的图片存储是按照当天的年月日作为文件夹,使用uuid去除
-,再加上之前的文件后缀名作为文件名来存储文件的
第一种方法:直接提取
/**
* 从图片url中获取文件名称
* @param url 文件存储路径
* @return 返回文件名称
*/
public static String getFileNameFromUrl(String url){
// 编写正则表达式
String regFileName = "([0-9]+\\/)+([a-zA-Z0-9]+)\\.(jpg|png|jpeg)";
// 匹配当前正则表达式
Matcher matcher = Pattern.compile(regFileName).matcher(url);
// 定义当前文件的文件名称
String fileName = "";
// 判断是否可以找到匹配正则表达式的字符
if (matcher.find()) {
// 将匹配当前正则表达式的字符串即文件名称进行赋值
fileName = matcher.group();
}
// 返回
return fileName;
}
第二种方法:将不用的部分替换为空字符串
/**
* 从图片url中获取文件名称
* @param url 文件存储路径
* @return 返回文件名称
*/
public static String getFileNameFromUrl(String url){
return url.replaceAll("^(http|https)\\:\\/\\/([a-zA-Z\\-]+\\.)+(com|cn)\\/", "")
.replaceAll("\\?([a-zA-Z]+\\=[a-zA-Z0-9\\.]+\\&)+([a-zA-Z]+\\=[a-zA-Z0-9\\%]+)$", "");
}
- url一般的格式:
https://wenzea.oss-cn-beijing.aliyuncs.com/2022/02/12/b0d3d337eea9485e82d84c5f16fabc9f.jpg?Expires=3599658873&OSSAccessKeyId=TMP.3KeAjOmPlD3MRVM6a5Qb9NwZTMvTgDiHt6PjZy6cVjJnK5HHHDLP4O9BDzgUBdYgTCyyjFFPOWNJ6gfln6zEBvabi416j&Signature=BhMCetPDgxdXpPFG3fxpsowg3SNzQ3D - 而提取出来的文件名称是:
2022/02/12/b0d3d337eea9485e82d84c5f16fabc9f.jpg
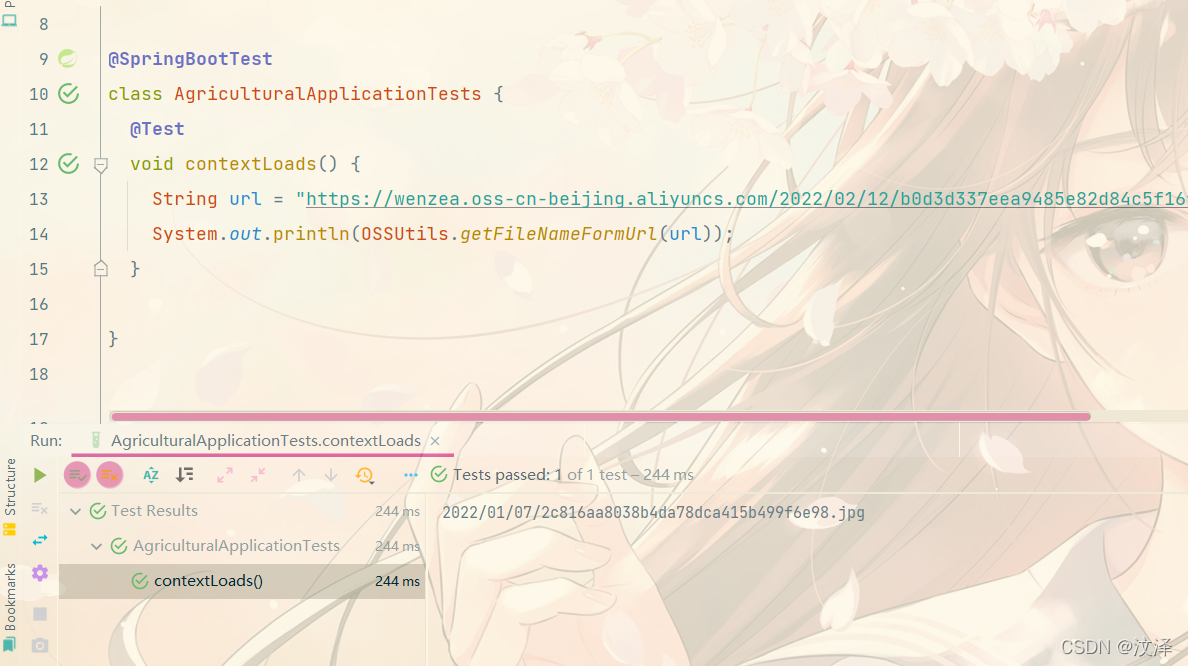
可以看到,在测试方法中已经成功的将文件名称提取出来了。

